kube-proxy 的转发模式可以通过启动参数–proxy-mode进行设置,有userspace、iptables、IPVS等可选项。
usersapce这里就不做赘述了, 由于转发是在用户态。所以效率不高,且容易丢包。 所以被废弃了。
iptables 模式
1 | 在这种模式下缺点就是在大规模的集群中,iptables添加规则会有很大的延迟。因为使用iptables,每增加一个svc都会增加一条iptables的chain。并且iptables修改了规则后必须得全部刷新才可以生效。 |
iptables是用户态应用程序,通过配置NetFilter规则表构建Linux内核防火墙。
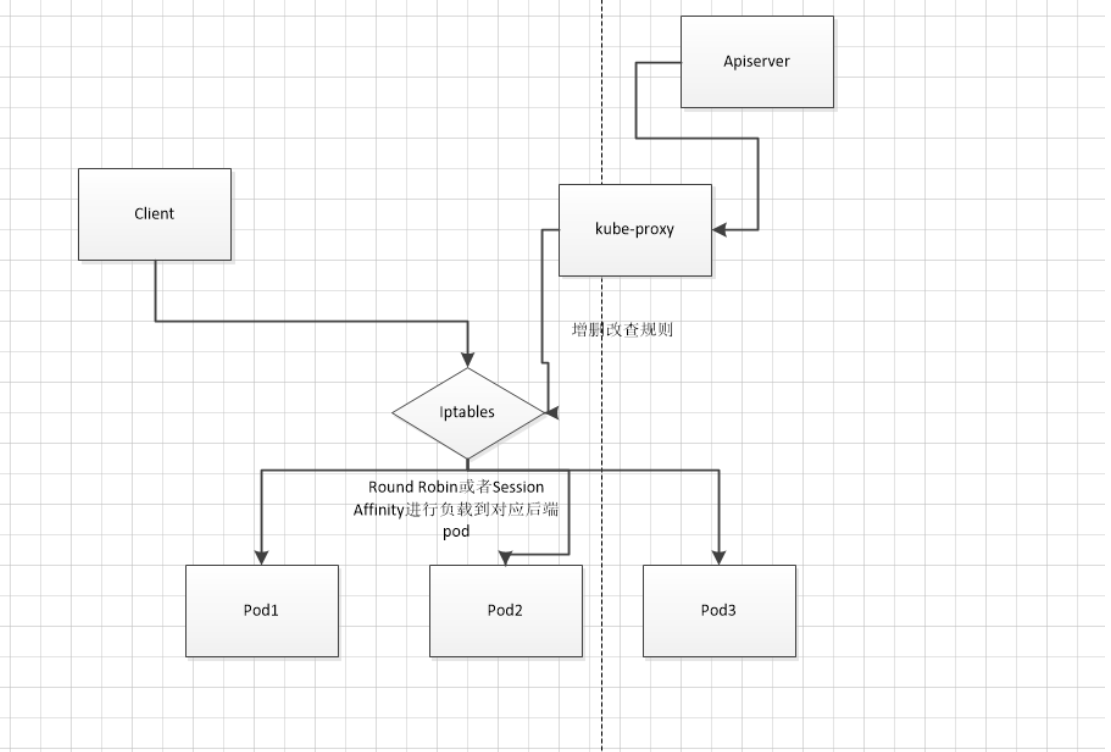
iptables模式与userspace模式最大的区别在于,kube-proxy 利用iptables的DNAT模块,实现了Service 入口到Pod实际地址的转换,免去了一次内核态到用户态的切换。
例子
以下面Service为例,分析kube-proxy创建的iptables规则。
1 | apiVersion: v1 |
如上所示,在本例中我们创建了一个NodePort类型名为tomcat的服务。该服务的端口为6080,NodePort为30005,对应后端Pod的端口也为6080。虽然没有显示,但是它的Cluster IP为10.254.0.40。tomcat服务有两个后端Pod,IP分别是192.168.20.1和192.168.20.2。
kube-proxy 为该服务创建的iptables规则如下:
1 | # iptables -S -t nat |
逐条分析。首先,如果是通过节点的30005端口访问NodePort,则会进入以下链,kube-proxy针对NodePort流量入口创建了KUBE-NODEPORTS 链。在我们这个例子中,KUBE-NODEPORTS 链进一步跳转到KUBE-SVC-67RLXXX链。
1 | -A KUBE-NODEPORTS -p tcp -m -comment --comment "default/tomcat:"\ |
再看下面的规则,这里采用了iptables的random模块,使连接有50%的概率进入KUBE-SEP-ID6YXXX链,50%的概率进入KUBE-SEP-IN2YXXX链。因此,kube-proxy的iptables模式采用随机数实现了服务的负载均衡。
1 | -A KUBE-SVC-67RLXXX -m comment --comment "default/tomcat:" -m \ |
KUBE-SEP-ID6YXXX 链的具体作用就是将请求通过DNAT发送到192.168.20.1的6080端口。
1 | -A KUBE-SEP-ID6YXXX -s 192.168.20.1/32 -m -comment --comment "default/tomcat:"\ |
当然,做完dnat后也需要snat
1 | 客户端C发起对一个服务S的访问,假设目的地址是(C,VIP),那么客户端期待得到的回程报文的源地址是VIP。即回程报文的源和目的地址应该是(VIP,C)。当网络报文经过网关(Linux内核的netfilter,包括iptables和IPVS director)进行一次DNAT后,报文的源和目的地址对呗修改成了(C,S)。当报文送到服务端S后,服务端一看报文源地址是C,便直接把响应报文返回给C,此时响应报文的源目的地址对是(S,C)。这与客户端期待报文源和目的地址不匹配,客户端收到后悔简单丢弃该报文。 |
结果显示
综上所述,iptables模式最主要的链是KUBE-SERVICES、KUBE-SVC-和KUBE-SEP-。
- KUBE-SERVICES 链是访问集群内服务的数据包入口点,它会根据匹配到的目标IP:port将数据包分发到相应的KUBE-SVC-*链
- KUBE-SVC-链相对于一个负载均衡器,它会将数据平均分发到KUBE-SEP-链,每个KUBE-SVC-链后面的KUBE-SEP-都和Service的后端Pod数量一样。
- KUBE-SEP-*链通过DNAT将连接目的地址和端口从Service的IP:port替换为后端Pod的IP:port,从而将流量转发到相应的Pod。
iptables模式与userspace模式相比,虽然在稳定性和性能上均有不小的提升,但因为iptables使用NAT完成转发,也存在不可忽视的性能损耗。另外,当集群中存在上万服务时,Node上的iptables rules会非常庞大,对管理是个不小的负担,性能还会大打折扣。
ipvs 模式
IPVS是LVS的负载均衡模块,亦基于netfilter,但比iptables性能更高,具备更好的可扩展性。kube-proxy的IPVS模式在kubernetes1.11版本达到稳定。
先来了解一下为什么添加IPVS的原因,随着kubernetes集群规模的增长,其资源的可扩展性变得越来越重要,特别是对那些运行大型工作负载的企业,其服务的可扩展性尤其重要。要知道,iptables难以扩展到支持成千上万的服务,它纯粹是为防火墙设计的,并且底层路由表的实现是链表,对路由规则的增删改查操作都要涉及便利一次链表。
尽管kubernetes 1.6版本已经支持5000节点,但使用iptables模式的kube-proxy实际上是将集群扩展到5000节点的最大瓶颈。假设,我们有1000个服务,每个服务有10个后端Pod,将会在工作节点上至少产生10000*N(N>=4)个iptables记录,这可能使内核非常繁忙的处理每次iptables规则的刷新。
并且,使用IPVS做集群内服务的负载均衡可以解决iptables带来的性能问题。IPVS专门用于负载均衡,并使用更高效的数据结构(散列表),允许几乎无限的规模扩张。
IPVS 的工作原理
IPVS是Linux内核实现的四层负载均衡,是LVS负载均衡模块的实现。IPVS基于netfilter的散列表,相对于同样基于netfilter框架的iptables有更好的性能表现和扩展性。
IPVS支持TCP、UDP、SCTP、IPv4、IPv6等协议,也支持多种负载均衡策略,例如rr、wrr、lc、wlc、sh、dh、lblc等。IPVS通过persistent connection 调度算法原生支持会话保持功能。
LVS工作原理,简单来说。当外机的数据包首先经过netfilter的PERROUTING链,然后经过一次路由抉择到达INPUTU链,再做一次DNAT后经过FORWARD链离开本机网络路由协议栈。由于IPVS的DNAT是发生在netfilter的INPUT链,因此如何让网络报文经过INOUT链在IPVS中就变得非常重要。一般有两种解决方法,一种是把服务的虚IP写到本机的本地内核路由表中;另一种方法是在本机创建一个dunmmy网卡。然后把服务的虚IP绑定到该网卡上。kubernetes使用的是后者。
IPVS支持三种负载均衡模式:Direct Routing(简称DR),Tunneling(也称ipip模式)和NAT(也称Masq模式)
注:虽有一些版本的IPVS,例如华为和阿里自己维护的分支支持fullNAT,及同时支持SNAT和DNAT,但是Linux内核原生版本的IPVS只做DNAT,不做SNAT。因此在kubernetes service 的某些场景下,我们仍然需要iptables。
DR
IPVS的DR模式是最广泛的IPVS模式,它工作在L2,即通过Mac地址做LB,而非IP地址。在DR模式下,回程报文不会经过IPVS director 而是直接返回给客户端。因此,DR在带来高性能的同时,对网络也有一定的限制,及要求IPVS的director 和客户端在同一个局域网。另外,比较遗憾的是,DR不支持端口映射,无法支持kubernetes service的所有场景。
Tunneling
IPVS的Tunneling模式就是用IP包封装IP包,因此也称ipip模式。Tunneling模式下的报文不经过IPVS director,而是直接回复给客户端。Tunneling模式统一不支持端口映射,因此很难被用在kubernetes的service场景中。
NAT
IPVS的NAT模式支持端口映射,回程报文需要经过IPVS director,因此也称Masq(伪装)模式。kubernetes在用IPVS实现Service时用的正式NAT模式。当使用NAT模式时,需要注意对报文进行一次SNAT,这也是kubernetes使用IPVS实现Service的微妙之处。
kube-proxy IPVS模式参数
在运行基于IPVS的kube-proxy时,需要注意以下参数:
- –proxy-mode:除了现有的userspace和iptables模式,IPVS模式通过–proxymode=ipvs进行配置。
- –ipvs-scheduler:用来指定ipvs负载均衡算法,如果不配置则默认使用round-robin(rr)算法。
1 | 如果不配置则默认使用round-robin(rr)算法。支持配置的负载均衡算法有: |
- –cleanup-ipvs:类似于–cleanup-iptables参数。如果设置为true,则清除在IPVS模式下创建的IPVS规则;
- –ipvs-sync-period:表示kube-proxy刷新IPVS规则的最大间隔时间,例如5秒。1分钟等,要求大于0;
- –ipvs-min-sync-period:表示kube-proxy刷新IPVS规则最小时间间隔,例如5秒,1分钟等,要求大于0
- –ipvs-exclude-cidrs:用于清除IPVS规则时告知kube-proxy不要清理该参数配置的网段的IPVS规则。因为我们无法区别某条IPVS规则到底是kube-proxy创建的,还是其他用户进程的,配置该参数是为了避免删除用户自己的IPVS规则。
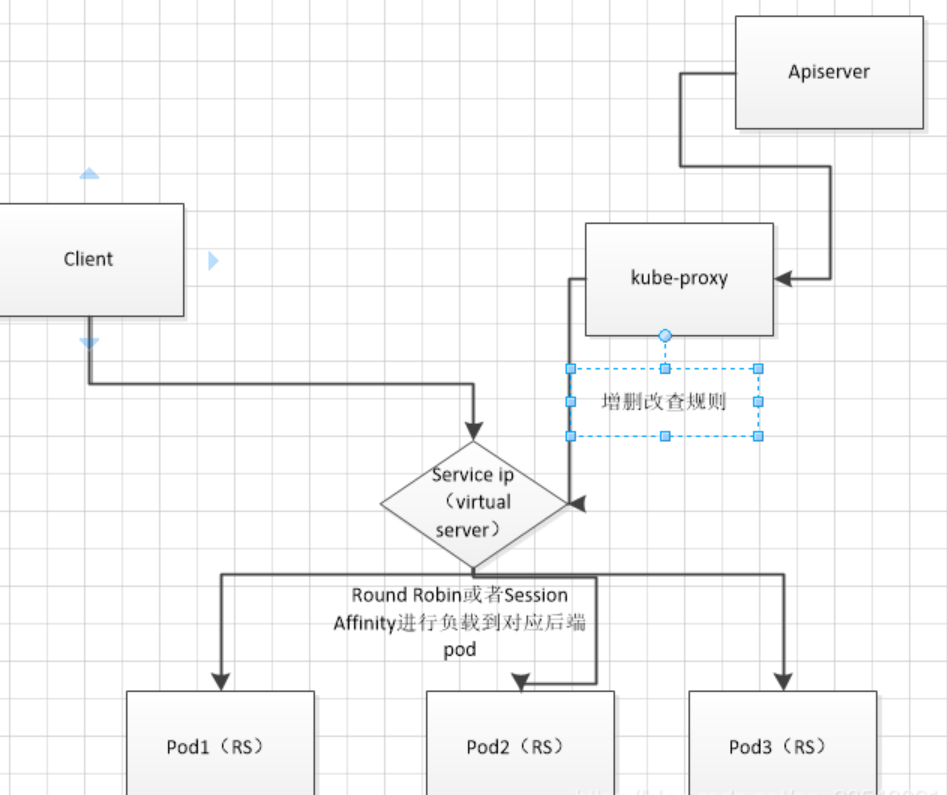
1 | 一旦创建一个Service和Endpoint,IPVS模式的kube-proxy会做以下三件事: |
IPVS模式中的iptables和ipset
IPVS用于流量转发,它无法处理kube-proxy中的其他问题,例如包过滤、SNAT等。具体来说,IPVS模式的kube-proxy将在以下4中情况依赖iptables
- kube-proxy 配置启动参数masquerade-all=true,即集群中所有经过Kube-proxy的包都将做一次SNAT
- kube-proxy 启动参数指定集群IP地址范围
- 支持Load Balance 类型的服务,用于配置白名单
- 支持NodePort类型的服务,用于在包跨节点前配置MASQUERADE,类似于上文提到的iptables模式
我们不想创建太多的iptables规则,因此使用了ipset减少iptables规则,使得不管集群内有多少服务,IPVS模式iptables规则的总数在5条以内。

